Introduction: The Journey from Keys to Federation In the early days of…
Subscribe Newsletter
Subscribe to our news letter to get the latest on Google Cloud Platform and more!
Creating a recommendation engine is a fascinating journey filled with exciting challenges. For my project, I started with an old Netflix dataset from Kaggle, which contained ratings given by users to various movies. After cleaning the data using a Spring Batch application deployed as a Cloud Run Job (something I’ve written about in an earlier blog), I faced the next big step: preparing the data for analysis and storage.
This step was pivotal. I needed to ensure the data was clean, structured, and accessible for analysis—ready to uncover insights and eventually power the machine-learning model for recommendations.
Enter Google Dataflow: my go-to solution for scalable data processing and transformation.
The Problem: Preparing Data for BigQuery
Let’s break down the requirements:
Data Ingestion: The cleaned data was sitting in Google Cloud Storage (GCS) as text files. I needed a way to read this data efficiently.
Data Transformation: The raw data required additional processing, like parsing rows into structured formats, filtering invalid records, and computing aggregates (e.g., average ratings for each movie).
Data Storage: Finally, the transformed data needed to be loaded into BigQuery, where I could run SQL queries and explore patterns.
While I could directly upload the text files to Vertex AI for training, this approach had some glaring issues:
Lack of Transformations: Vertex AI expects data in a ready-to-train format, but my raw data wasn’t there yet.
Inflexible Exploration: Without BigQuery, I couldn’t easily analyze trends like user preferences or movie popularity before building the model.
Scalability Concerns: Direct uploads might work for small datasets, but for larger, more complex datasets, scaling would be a challenge.
Why Dataflow?
This is where Google Dataflow shines. It’s a fully managed, serverless service for stream and batch data processing, built on the Apache Beam programming model. Here’s why it was the perfect choice:
Unified Data Processing: Dataflow can handle both batch (like my preprocessed text files) and streaming data. This flexibility means I can later extend the pipeline to process real-time events if needed.
Serverless Scaling: Dataflow automatically scales up or down based on the size of the data, so I don’t need to worry about infrastructure management.
Custom Transformations: Apache Beam’s SDK lets me define custom logic to clean, transform, and enrich data—essential for parsing rows, validating formats, and calculating metrics.
Seamless Integration: Dataflow integrates natively with GCS, BigQuery, and other Google Cloud services, making it easy to move data through the pipeline.
Cost Efficiency: You pay only for the resources you use, and by optimizing the pipeline, costs can be minimized.
Designing the Pipeline
To make things simple, I structured the pipeline into three stages:
1. Reading Data from GCS
The pipeline begins by ingesting text files from a GCS bucket. Each file contains lines of data in this format:
To handle this, I built a utility class GCSFileReader that validates the file path and uses Apache Beam’s TextIO.Read to read the data:
public TextIO.Read read(String filePath) {
if (filePath == null || filePath.isEmpty()) {
throw new MissingArgumentException("File path cannot be null or empty.");
}
return TextIO.read().from(filePath);
}
2. Transforming Data
Parsing and Structuring
Next, the raw text lines are parsed into a structured format using a custom DoFn called MovieCustomerPairFn. This function splits each line into fields (e.g., movie_id, customer_id, rating, date) and validates the data:
public void processElement(ProcessContext context) {
String line = context.element().trim();
String[] fields = line.split(",");
if (fields.length != 4) return; // Skip invalid rows
RatingInfo ratingInfo = new RatingInfo(fields[0], fields[1], Integer.parseInt(fields[2]), fields[3]);
context.output(ratingInfo);
}
Computing Aggregates
To calculate metrics like the average rating per movie, I used a custom CombineFn. This function accumulates ratings for each movie and computes the average:
@Override
public AverageAccumulator mergeAccumulators(Iterable<AverageAccumulator> accumulators) {
AverageAccumulator merged = new AverageAccumulator();
for (AverageAccumulator acc : accumulators) {
merged.merge(acc);
}
return merged;
}
3. Writing to BigQuery
Finally, the structured and enriched data is written to BigQuery. To ensure compatibility, I defined a schema in BigQuerySchemaUtils:
public static TableSchema getRatingInfoSchema() {
List<TableFieldSchema> fields = List.of(
new TableFieldSchema().setName("movie_id").setType("STRING").setMode("REQUIRED"),
new TableFieldSchema().setName("customer_id").setType("STRING").setMode("REQUIRED"),
new TableFieldSchema().setName("rating").setType("INTEGER").setMode("REQUIRED"),
new TableFieldSchema().setName("date").setType("STRING").setMode("REQUIRED")
);
return new TableSchema().setFields(fields);
}
Behind the Scenes: How Dataflow Works
When you deploy a pipeline, Dataflow takes care of the following:
Job Management: It converts your Apache Beam code into an optimized execution graph.
Resource Provisioning: It allocates virtual machines and scales them based on the data size.
Fault Tolerance: If a node fails, Dataflow retries and ensures consistency without your intervention.
Performance Optimization: Through features like autoscaling and data shuffling, it minimizes execution time.
Benefits of Using Dataflow Over Alternatives
Compared to Manual Scripts: Dataflow abstracts infrastructure management and scaling, so you can focus on logic.
Compared to Direct Uploads to Vertex AI: Dataflow allows transformations and quality checks before storage, ensuring clean data.
Compared to Other ETL Tools: Dataflow’s native integration with Google Cloud and support for both batch and streaming make it uniquely versatile.
Observing Pipeline Execution in Dataflow: Metrics, Insights, and Debugging
One of the standout features of Google Dataflow is its comprehensive monitoring and debugging capabilities. When you’re working on a data pipeline, especially for a critical application like a recommendation engine, visibility into how your pipeline is performing is invaluable. Dataflow’s execution details and metrics allow you to:
Track progress: Understand how far along your job is and see detailed execution stages.
Identify bottlenecks: Spot which parts of your pipeline are slowing things down.
Debug errors: Pinpoint where things are failing and why.
Optimize performance: Use metrics to fine-tune your pipeline for better efficiency and cost savings.
How to Monitor Your Dataflow Pipeline
When you deploy a Dataflow job, it appears in the Google Cloud Console under the “Dataflow” section. Clicking on your job opens the Job Details page, where you can explore several key aspects:
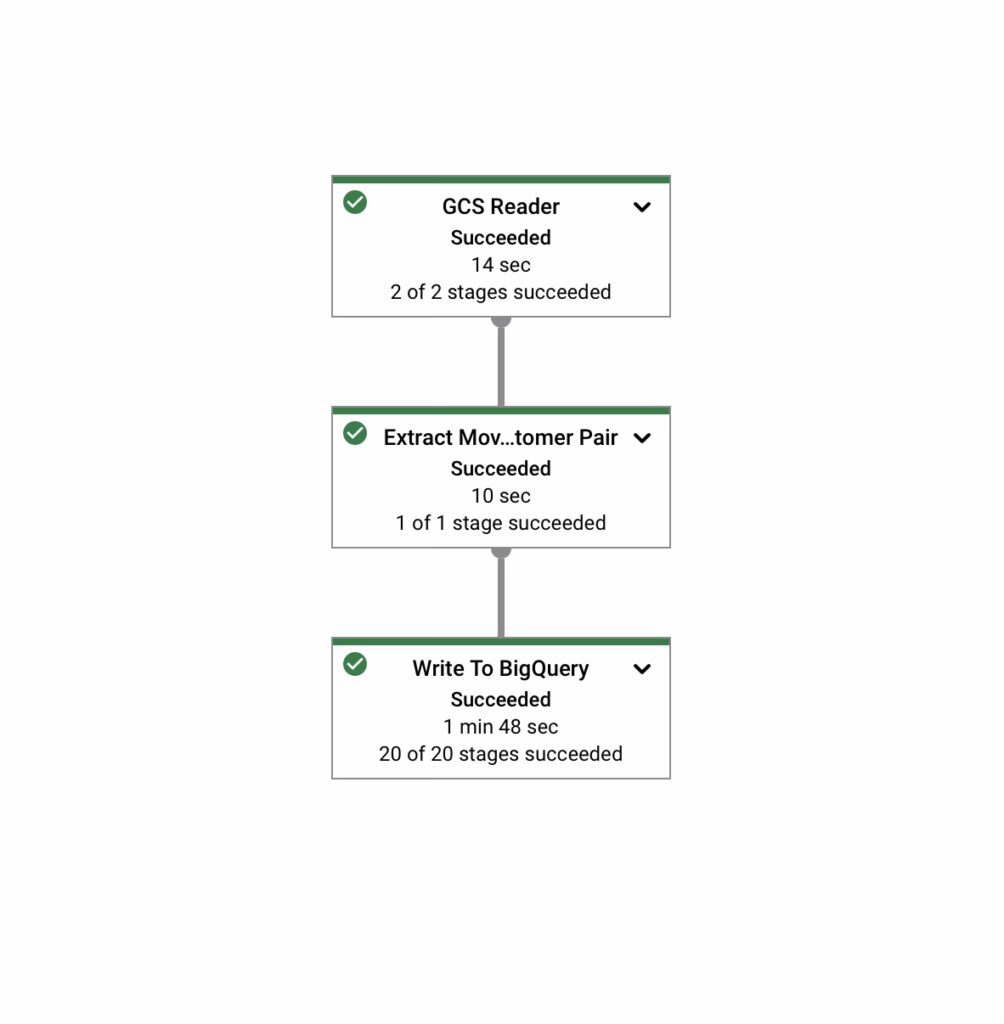
1. Pipeline Visualization
The visualization graph in Dataflow is one of the first things you’ll notice. It represents your pipeline as a directed acyclic graph (DAG), showing each step (or transform) as a node. This graph allows you to:
View dependencies: See how data flows between stages of the pipeline.
Inspect individual transforms: Click on a step to see its input/output data sizes, processing time, and status (e.g., running, succeeded, or failed).
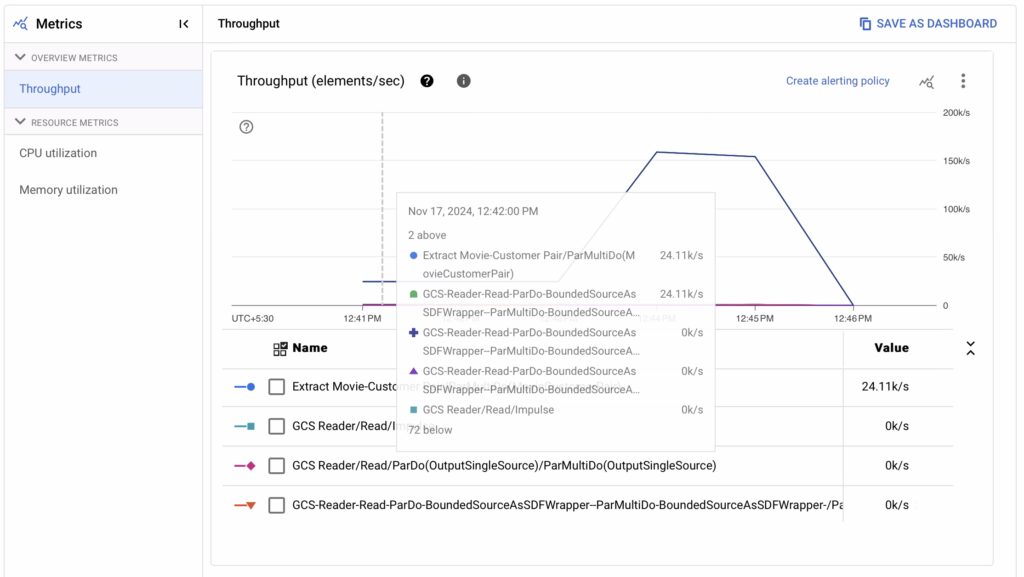
2. Metrics Dashboard
The metrics dashboard provides real-time statistics about:
Data Throughput: How much data is being processed per second at each stage.
Element Count: Total number of elements processed by each transform.
System Latency: Time taken for each stage to process data.
Worker Utilization: Insights into how effectively resources (e.g., VMs) are being used.
For instance, when working on my recommendation engine, I noticed that the “Parse Movie Ratings” transform had a higher latency because of unexpected invalid rows. This prompted me to add better validation logic in my DoFn class.
3. Job Logs
Dataflow logs provide detailed output for every stage of your pipeline. They are categorized into:
INFO Logs: General pipeline activity (e.g., job starting, data shuffling).
WARNING Logs: Non-critical issues like input rows with missing fields.
ERROR Logs: Critical issues that could cause the pipeline to fail.
Using these logs, I was able to trace malformed records in my dataset, which helped me refine the pipeline’s error-handling logic.
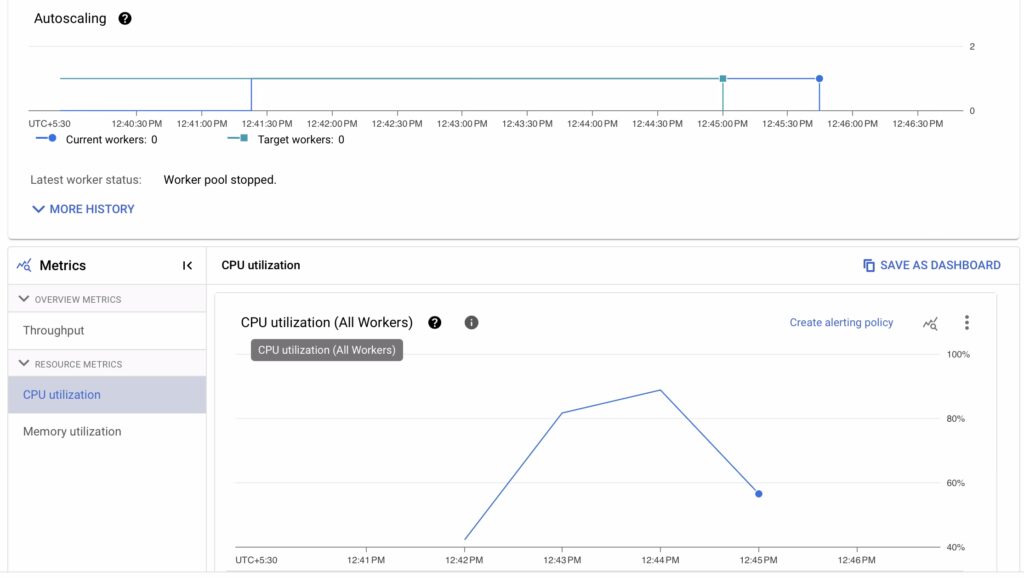
4. Worker Insights
If your pipeline runs on multiple workers, the “Workers” tab in the UI gives granular details about:
CPU and memory usage per worker.
Autoscaling behavior—how the number of workers adjusts dynamically.
Processing time for individual tasks.
This helped me confirm that my pipeline was effectively scaling down when processing smaller datasets, saving costs.
GitHub Repository
For those interested in exploring the code behind this blog post and replicating the setup, I’ve made the entire project available on GitHub. You can find the repository, including the Dockerfile, GitHub Actions workflows, and the Spring Batch code, in the link below:
Feel free to fork the repository, explore the setup, and adapt it to your own projects. If you have any questions or suggestions, don’t hesitate to open an issue or contribute to the project!
What Comes Next?
Now that the data is loaded into BigQuery, I’ll spend some time analyzing it—finding trends, exploring user behavior, and identifying potential features for the recommendation engine. This exploratory phase will lay the groundwork for designing the model.
In the next blog, I’ll share how I use BigQuery for analysis and transition the data to Vertex AI for building the machine-learning model.
Conclusion
Google Dataflow is an incredibly powerful tool for data engineering. Its ability to scale, transform, and integrate with other Google Cloud services makes it indispensable for workflows like building a recommendation engine. By structuring the pipeline effectively, I’ve ensured that the data is clean, enriched, and analysis-ready, setting the stage for the next steps in the project.
If you’re working on a similar pipeline, I’d love to hear your thoughts or questions! Let’s build together!